Configuring Models
- Print
- DarkLight
Configuring Models
- Print
- DarkLight
Article summary
Did you find this summary helpful?
Thank you for your feedback
Model configuration is the core capability of the AI Data Pipeline. It provides an interface for you to define the configurations that will act as a set of instructions for the AI Data Pipeline as it produces your unified data model.
The AI Data Pipeline applies these user instructions to incoming machine and manufacturing system data record streams, and then leverages patent pending algorithms to render data models that represent your production processes.
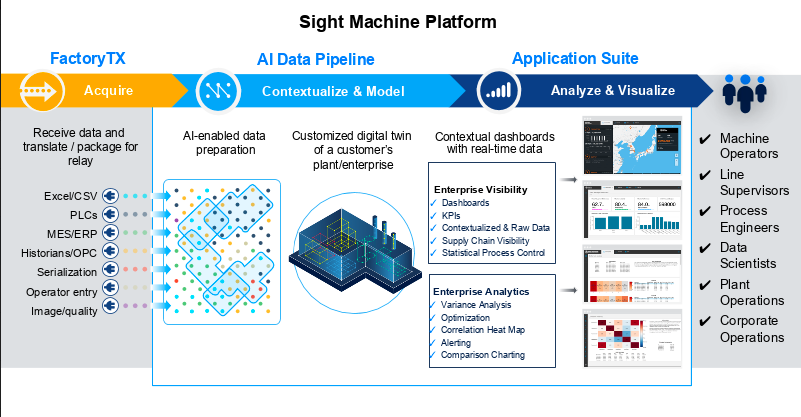
Sight Machine AI Data Pipeline User Configuration Data Flows
Individual data models serve as the foundation for a unified data model representing the entire production process that enables Sight Machine’s applications to deliver unique insights into a manufacturer’s operations.
Currently, Sight Machine supports the configuration of Facilities, Machine Types, and Machines. This is sufficient for the production of a Cycles model, a Downtimes model, and OEE metrics.
About Time Sequencing
In order to model streaming data in near real time, Sight Machine blends, joins, and integrates data streams from multiple sources. To establish relationships between disparate data types and sources, the AI Data Pipeline tags data records with timestamps at various points in the data acquisition process. At this point, each manufacturing data packet contains at least two time fields:
- data.timestamp: A field within the raw data that indicates the time when the raw data was generated. This field is the critical element used to order, group, and blend data from the various incoming data streams, and is used by the Sight Machine platform for all downstream calculations, like cycle boundaries, downtime boundaries, etc.
- capturetime: This field indicates the time that the Sight Machine software captured the data from its original source.
NOTE: It is assumed that you are working with real-time data that is in order. If you are working with high-latency data or a blend of data that is coming in at different times, contact Sight Machine for support and assistance.
How Cycles Affect the Modeling Process
For the AI Data Pipeline to properly model data, each signal or data stream from an individual sensor must have a discrete value or set of values for each cycle. Typically, each signal would be distilled to one value; rarely must all signals be represented in the data to produce a useful model. Process or data engineers with expertise in the production process at each facility are usually best equipped to define the rules for establishing these cycle values. After these rules are defined, the AI Data Pipeline will automate the method of establishing values for each cycle to the streaming data.
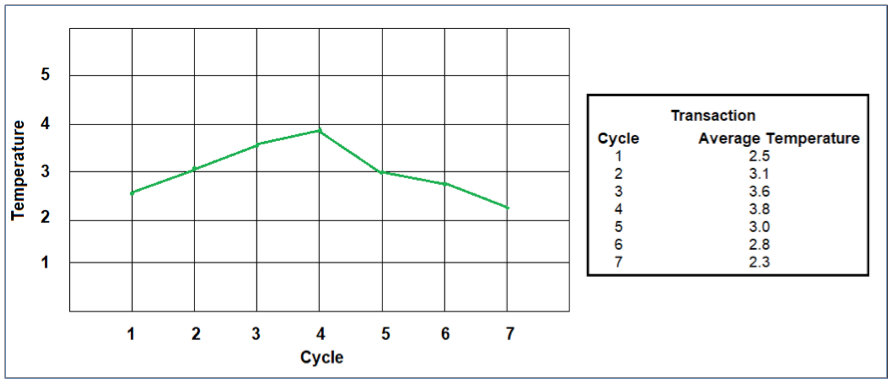
For many signals, using an average of the continuous time series values captured during a cycle provides the appropriate level of fidelity for constructing the data model. In the first example, you can see that for continuous temperature data, you could model and visualize the average temperature over a number of cycles.
Example 1: Modeling Continuous Data
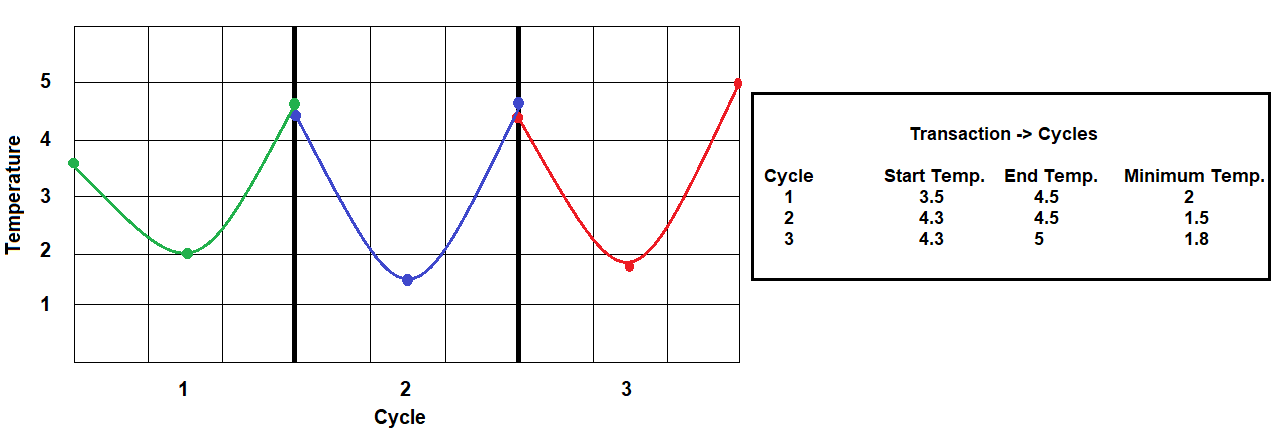
In the second example, for a data stream that varies significantly during the duration of a cycle, capturing the start, end, and minimum temperature values generate a more accurate model than a simple average.
Example 2: Modeling Periodic Data
Establishing these rules for determining the discrete value(s) of each signal or data stream from an individual sensor for each cycle is a critical element of user configuration. The AI Data Pipeline provides an easy-to-use interface for defining these rules for each Data Field in the Machine Type configurations.